CHILE 2014
Chile-Harvard Innovative Learning Exchange (CHILE) 2014
Task Description
The objective of our work was to develop a classifier of different types of stellar objects. The information available about those objects was the radius, the position in the sky in celestial coordinates, and the time series of 16 points (4 each night, 4 nights). We decided to use a decision tree for this purpose, in order to classify from general objects like galaxies or stars to specific subclasses of variable stars. The decisions include probabilities, so at the end we have a probability of belonging at each terminal class.
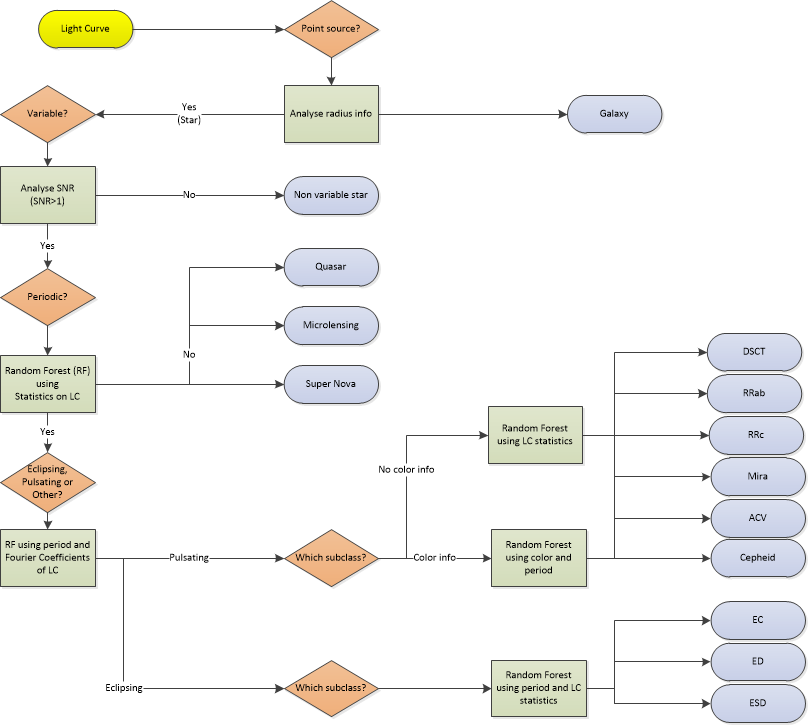
Star/galaxy clasifier
The information used for this classifier is only the radius information. Stars should be point sources, with a radius of less than a certain number of pixels and without big variations from one epoch to another.
Variability test
We found that the derived photometric error of our data tend to be too small, which made most of our sources look like variable, while realistically less than 10% of the stellar objects are variable. We thus first correct the error bars using the method introduced by Protopapas et al. (2013). The idea is that for a non-variable source, the error bar should be comparable to the interquartile range of the source magnitude. For Ns sources in a given CCD we fit an error correction parameter which minimizes
Where y_k and e_k are the magnitudes and error bars of the lightcurve of source k, respectively, iqr is the interquartile range and med is the median.
After the correction, we use the Stetson J index (Stetson 1996) to test the variability of the source. It is a robust method to decide if a time series shows variability or not, relating the measurements and the error associated with those. The equations for that index are the following:
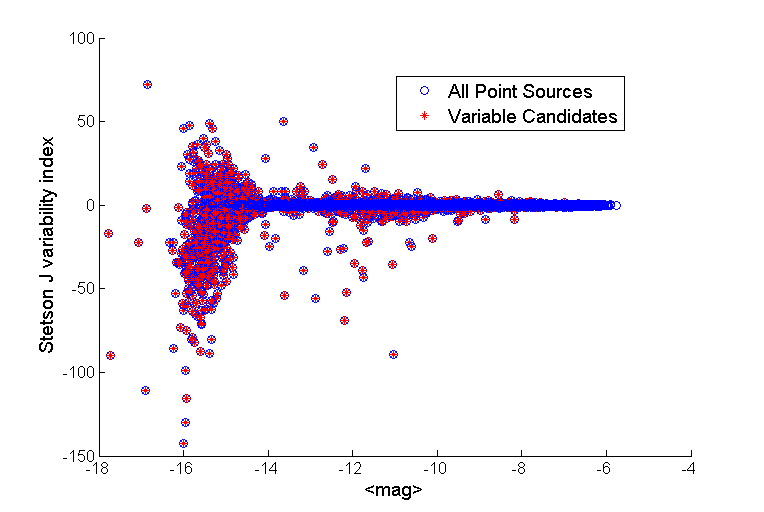
We use |J| >1 as a criteria for choosing variable candidates. In this step, 1780 out of 68739 point sources were labeled as variable candidates. Figure below highlights the variable candidates with red cross among all of our point sources shown with blue circles. In the figure is possible to see that objects with a Stetson J index close to zero are most likely non-variable object, while if the absolute value of the index is greater than zero, that object should be a variable one.
Periodic discrimination
One subclass of variable objects that are important to separate are the periodic ones. Although there are other variable stellar objects that also could be interesting to identify. With that idea, we developed a classifier that can associate probabilities of belong to every of the following classes:
The light curve information was obtained from several databases including:
OGLE (Optical Gravitational Lensing Experiment): periodic and microlensing database.
MACHO (MAssive Compact Halo Objects): quasar database.
CfA (Center for Astrophysics): SNe database.
This classifier is a random forest trained with statistical values obtained from the light curves of each object. Those statistics are the following:
| Statistic | Description |
| Standard Deviation | This statistic shows how much variation or dispersion from the average exists |
| Skewness | Statistic that measures the asymmetry of the distribution of the samples. In this cases, we compute the skewness of the flux measurements for each lightcurve. |
| Kurtosis | Another statistic related to the shape of the data. Kurtosis measures the peaks of the data, and how far away are from the mean. |
| Median Absolute Deviation | Measure related to the distance between the samples and the median value of them. It is robust when only few data points are available. |
| Interquartile Range | Measure of the dispersion of the distribution. It’s compute as the first quartile (we there is the higher 25% of the data) minus the third quartile (with the lower 25% of the data). |
| Stetson J index | Variability index |
| QSO index | Variability index for quasar identification. Proposed by Butler and Bloom on 2011. |
| Non-QSO index | Fit statistic for non-QSO variable star. |
Type of periodic star
After we decide that there is a chance that one source is periodic, we perform a classification between two kinds of periodic stars: Eclipsing and Pulsating. This is a rough classification, and in each class we can find several different subclasses, that are going to be used in forward decisions.
Once again, the Machine Learning algorithm used is Random Forest. This time the features used are related to the period and the shape of the lightcurves. We only use two features in this classifier: period, found by Lomb Scargle, and Fourier coefficient A_{21}. This coefficient is calculated as the ratio between the amplitudes of the second and first harmonic wave fitted to the light-curve.
This classifier performs almost perfectly on the training set, but in the real data that doesn’t happen. That is because the Fourier coefficient depends on the used period, so if the period is miscalculated, then the estimation of the coefficient is not going to be accurate. Nevertheless, if the amount of information increases, then the classification should be more robust.
Subtype of Pulsating star
In this stage we perform two different classifiers. That is because we look for the color information on the USNO-B1.0 (B and R) and 2MASS (J, H and Ks) catalog, but is not available for each stellar object that we have. The color information is useful to separate different classes of pulsating stars with more confidence. When we don’t have color information, we run a Random Forest classifier with the same statistical information than in the Periodic discrimination.
The different kinds of pulsating stars that we want to discriminate are:
Subtype of Eclipsing Star
For eclipsing variable stars, the color information is not useful, because this type is extrinsic. This means that the variability is not associated with the physical properties of the star. For this reason, this kind of stars may be on any color and in a broad range of periods. The classifier is trained again with statistical information and the fourier coefficients A21 and A31.
The subtypes of eclipsing stars that we want to classify are: